

登录|免费注册
 中文
中文ABOUT RDDC
关于RDDC
RDDC简介
罕见病数据库(以下简称“RDDC”)由清华珠三角研究院和赛业生物共同建设,于2021年2月立项,2022年2月正式推出1.0版本。经过一年的运营,RDDC获得大量科研和医疗工作者的关注,并收到许多宝贵的反馈意见。因此,我们对RDDC进行了迭代更新,并于2023年7月1日推出RDDC2.0版本。新版本RDDC在页面展示方式和数据交互方面做了优化,以更好的服务科研人员对于数据查询和数据挖掘的需求。同时,RDDC重点关注基因和遗传相关的数据呈现并专注于充分利用遗传大数据进行生物AI工具的开发。本数据库的宗旨旨在帮助医生、高校和研究机构的科研人员,以及罕见病患者及家属能够快速直观地对感兴趣的罕见病进行全面地了解(在不改变数据原貌的情况下尽可能地对数据进行图形化呈现),更快地对目标信息进行筛选(标签和分类系统,正在开发),另一方面也通过该数据库整合国内罕见病相关资源,为中国罕见病的科研工作提供数据基础。
RDDC希望通过建立一站式的基因、疾病、动物模型信息平台,让用户能够在最短的时间内完成从靶点基因发现,到靶点基因的表型和功能查询,以及选择获得当前市场上和靶点基因表型最相关的动物模型,从而快速制定研究路线,开展针对疾病致病基因的科学研究和药物发现工作。数据库提供的主要信息包括:
基因方面,RDDC收录了人类、小鼠、大鼠(计划中)等物种基因库信息,用户能从数据库中获得以下信息:
基因基本信息(ID、别称)和功能描述
人类、小鼠和大鼠中该基因信息比对
基因在染色体中的位置信息
基因突变展示
基因表达蛋白功能域
基因转录本信息
基因相关疾病信息(人类)
基因涉及表型信息(人类)
基因表达信息
基因表达的亚细胞定位(人类)
基因表达产物的相互作用蛋白
疾病方面,RDDC收录了Malacards、OMIM、Orphanet、ClinVar等开源数据库信息及罕见病联盟提供的本土疾病信息,用户能从数据库中获得以下信息:
不同数据库中对疾病基本信息的描述
疾病ID和疾病别名
疾病流行病学信息(更新中)
疾病的HPO相关描述
疾病相关基因列表及基因的突变类型分布
疾病相关药物研发进度
疾病相关临床试验信息
小鼠模型方面,RDDC收录了诸多文献中所使用的各类型基因编辑小鼠模型,用户能从数据库中获得以下信息:
小鼠模型基本信息
小鼠模型构建方式
涉及该基因编辑小鼠的杂交小鼠背景及表征的疾病
涉及该基因编辑小鼠的杂交小鼠的表型
涉及该小鼠的参考文献发表历史和文献链接
在对数据本身进行清洗,以及可视化展示之外。RDDC也同时将结构化后的数据应用于AI模型的训练。AI在生物医药的研究中的各个环节都有广阔的应用场景(图1)。RDDC致力于打通从罕见病靶点发现到罕见病药物上市后的所有AI应用场景模型的开发。目前RDDC的关注点还是集中在靶点发现阶段,其中已经完成了RNA剪接预测工具1.0版本和突变致病性预测模型1.0版本的开发工作。RDDC将从上游到下游,逐步通过开发AI工具,对药物开发流程中的生物学机理研究、潜在成药靶点、药物复杂反应、基因治疗药物优化、动物模型/人类成药转换、药物群体效应等复杂问题进行不懈的探究。
Biomedical Data Modalities

Machine Learning Models
Challenges & Opportunities
(图1)RDDC致力于将AI技术应用于罕见病药物开发全过程
目前已经上线的工具包括:
RNA剪接预测工具(RNA Splicer):用于预测碱基突变是否导致mRNA剪接位点发生变化,并对预测结果进行具体的分析和展示
突变致病性预测模型(Pathogenicity Predictor):用于对碱基突变导致的致病疾病等级(不限种类)利用机器学习里的xgboost 方法进行预测,其预测结果可以分为四个致病性等级:良性、疑似良性、疑似致病性和致病性
ASO 设计工具(ASO Designer):通过计算ASO与目标区域碱基序列的结合力及其他的碱基配对的指标(例如ASO的GC百分比,ASO的自由能量等),帮用户预测出数据集中的潜在候选序列
SNP可视化工具(SNP Viewer):可查看输入基因宏观的突变分布和突变状态, 为查询突变热点区域和位点提供便利
通路分析工具(Pathway Analysis):在线化的通路富集工具,富集之后能对通路中的所含有的基因表达量变化进行可视化展示,免去同类分析中的编程流程
关于罕见病
罕见病的定义在各个国家和地区之间存在一定差异,但一般是指发病率低于1/2000的疾病。由于单个罕见病病例缺乏,罕见病的研究进度整体而言与常见病,各种疾病以及疾病内部之间的分型并不明确,根据美国食品与药物管理(FDA)的统计,全球已知的罕见病约有7,000多种,而在分类更为细致的疾病数据库Malacards上的统计一共有14000多种。全球罕见病患者已超过3.5亿,患者中近50%为儿童。在这些罕见病中,仅有不到10%的疾病有已批准的治疗药物或方案。另外值得注意的一点是罕见病中的8成以上都是遗传或者基因相关的疾病,其中更是有相当部分为单基因疾病,这也是很多基因疗法的集中于罕见病的原因。
罕见病占疾病总数超过2/3
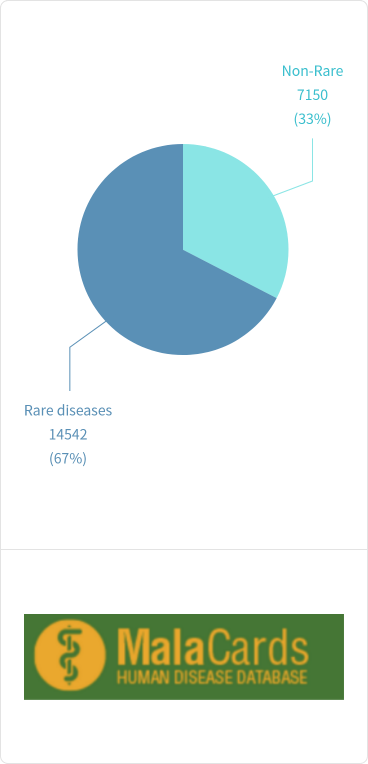
Malacards疾病分类中罕见病占比
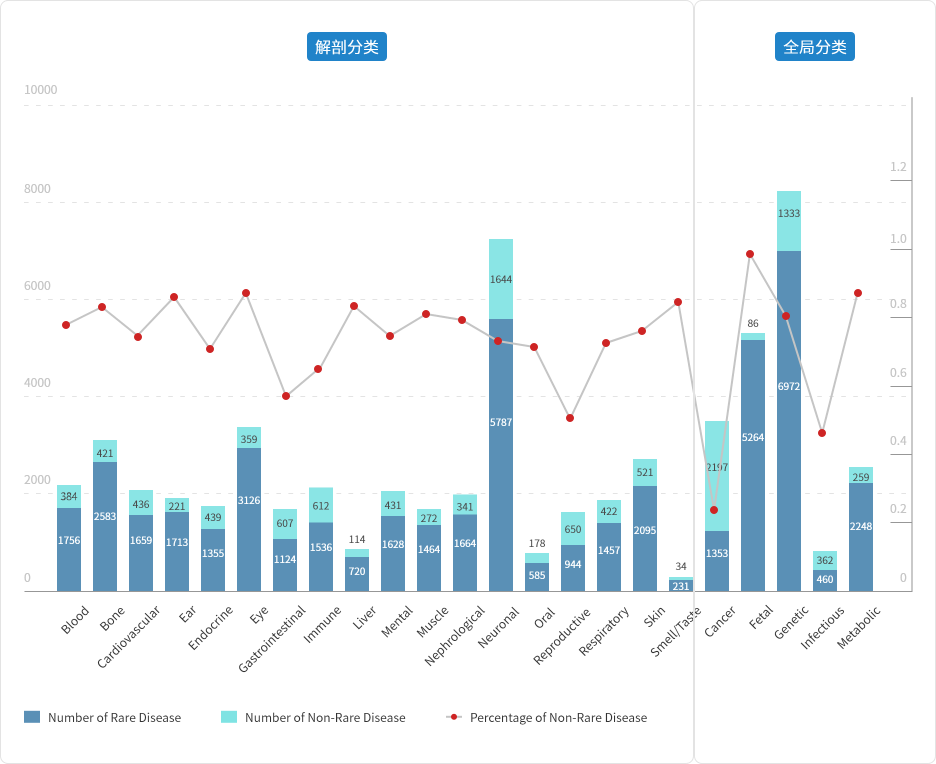
(图2)罕见病种类众多
由于我国人口众多,现有近2000万罕见病患者,2018年国家卫健委、科技部、工信部、药监局和中医药管理局联合发布《第一批罕见病目录》,以促进罕见病的诊疗,共121种罕见病纳入目录,包括遗传性肾炎(即Alport综合征)、渐冻症(肌萎缩侧索硬化)、血友病等。但由于更多罕见病缺乏好的动物模型和受众人群少,罕见病药物的研发总体投入较少。
在罕见病信息整合方面,由北京协和医院牵头,全国多家知名医院参与的罕见病注册系统于2020年上线,该系统致力于整合多家医院的科研和治疗资源,集中国内病理病例信息,解决罕见病信息孤岛困局。此外,美国的NIH和欧洲的NORD都做出了相当的努力,很多罕见病相关的非盈利机构也积极行动了起来,但目前罕见病信息仍然以临床试验和疾病基本信息为主,对临床前重要的疾病模型信息并没有很好地进行结构化处理; 另一方面以小鼠模型为核心的MGI数据库则将重心放在了小鼠模型的表型整理上,与临床信息结合并不紧密。而以结构化罕见病流行病学和标准命名信息为主要内容的Orphanet中的信息仍然以数据包的形式进行存储,并没有进行很好地展示,结合目前罕见病“孤岛式”的研究现状以及基因编辑技术发展带来的罕见病研究热度升温,所以目前对罕见病数据库不仅要求数据本身的高质量,对数据库的内容展示也提出了更高的要求。此外,随着AI在生命科学中如小分子药物发现,大分子结构预测,病理图片识别等多个领域发挥着越来越重要的作用,如何用AI对基因突变造成的罕见病进行预测以及治疗性病毒载体进行都将成为大健康领域潜在的重大突破。
RDDC的搭建,希望能为患者、医生、科研人员提供一个一站式的疾病-基因-动物模型-AI工具助力的信息可视化交互平台,为所有致力于罕见病治疗或者研究的人员提供最大程度的便利。




