

Nature主刊 | 我国人群的泛基因组参考图谱
近日,复旦大学、西安交大、中国医学科学院等26家单位联合发布了中国人群泛基因组联盟(CPC)一期研究进展。6月14日,相关成果以《基于36个族群的中国人泛基因组参考图谱》(“A Pangenome Reference of 36 Chinese populations”)为题发表于《自然》(Nature)。据悉,这是我国学者领导的人群基因组研究首次发表在《自然》主刊。

图1.Nature官网截图
这项研究初步构建了我国人群的泛基因组参考图谱,发现了在人类通用参考基因组上缺失的约1.9亿个碱基对的参考序列;新鉴定了约580万个点突变或小变异以及3.4万个结构变异,涉及大量潜在功能原件包括至少1367个蛋白质编码基因;并发现通用参考基因组上缺失的参考序列富集了适应性演化和起源于远古人类的遗传变异,并且与角质化、紫外线辐射应激、DNA 修复、免疫反应以及寿命等表型或功能相关。这项研究也显示了,建立我国自己的人群泛基因组图谱十分必要。在重构人类演化历程、挽回复杂疾病研究时“丢失的遗传率”等研究和应用中,该图谱具有巨大的潜在价值。
人类参考基因组是广泛用于人类遗传学和医学研究的遗传密码“导航图”,也是解析人类起源与演化、解析人类表型和疾病的遗传基础的根基。上世纪末“人类基因组计划”启动后的20年里,人类参考基因组作为生命、医学等研究领域的基石见证着人类在探索生命奥秘的漫漫征途上留下的或深或浅的足迹。从2001年首次发表人类基因组草图,人类参考基因组经历了数十次的更新迭代,发展到目前广泛使用的第38版本(GRCh38)。直到2022年从“端粒到端粒”联盟(T2T)构建的“无缺口”的T2T-CHM13参考基因组完成图,所有涉及人类遗传学的研究仍然依赖于线性参考基因组。今年正值国际人类基因组计划(HGP)完成20周年,人类参考基因组从“线性一维序列”过渡到“泛基因组多维图谱”。实际上,基因组的组装一开始就借助了数学中的“图论”思想和理论,加之计算机算法,实现了特定物种基因组元件的顺序排列。泛基因组(Pangenome)进一步借助图论的思想和计算技术,将人类多个族群的代表性样本的具有多样性的基因序列以多维图谱形式组装起来,形成一个能充分反映种群基因组结构变异多样性的导航图,从而指导进一步的遗传学和医学研究。
随着DNA测序和基因组组装技术以及计算分析方法的大幅改进,富含个体遗传多样性信息的图泛基因组替代线性基因组作为人类参考基因组的趋势将很快成为现实。在人类基因组计划成立之初,尽管中国作为唯一的发展中国家参与并为人类基因组参考图构建作出贡献,促成人类科技史的重要里程碑上刻有“中国”二字,但目前通用的人类参考基因组皆基于欧洲白人为主体样本构建,难以代表非欧裔族群、尤其我国族群的基因组多样性。即便是最新发表的人类泛基因组国际联盟(HPRC)收集了全球范围的46例样本,也仅包含3例中国汉族样本。
作为人口大国,我国巨大的人口基数和丰富的人群多样性是发展人类基因组学和精准医学的重要优势:西南部高原地区分布着众多藏缅、南亚语系族群,东西方人群在西北部丝绸之路沿线交融,苗瑶语族人群在云贵地区世代繁衍,蒙古、突厥人群曾游牧于北部风沙地,通古斯语族抵抗严寒一路向北,台-卡岱(侗台)族群的先辈亦曾穿梭于南方丛林河谷。悠久的人群历史、丰富的地理气候环境,塑造了中华民族独特的遗传多样性,构成了人类泛基因组研究不可或缺的东方画卷。构建能够代表中华民族遗传多样性的中国人群泛基因组图谱势在必行且迫在眉睫,这将极大提高捕获罕见或低频遗传变异的灵敏度和准确性,支撑服务中国人遗传多样性研究、复杂疾病分子机制研究和精准医学研究与应用。

图2.“中国人群泛基因组联盟”(CPC)一期36个族群画像集
为了构建高质量高精度的中国人群泛基因组参考图谱,复旦大学徐书华教授、西安交通大学叶凯教授联合国内26家单位发起了中国人群泛基因组联盟(Chinese Pangenome Consortium, CPC),旨在建立我国专属参考基因组和泛基因组资源和分析体系,形成我国自主可控的人类基因组资源与核心技术,支撑精准医学发展,服务“健康中国”战略。
在其第一期研究计划中,CPC对代表中国36个族群的58个样本采用最新的第三代高保真基因组测序技术进行了深度测序,结合最新的单倍型基因组组装方法,获取了116个高质量单倍型基因组,并以图基因组的方式构建了高质量中国人群参考泛基因组。该泛基因组图谱总共包含约3.01 Gb个碱基对的序列信息,在现有人类参考基因组的基础上新增了约1.9亿个碱基对的新序列,包含约590万个小变异(单核苷酸多态性变异和小规模插入/缺失变异)和约3.4万个结构变异(Structural variation, SV),涉及至少1367个蛋白编码基因复制事件等。其中,约500万个碱基对新序列存在于95%以上的单倍型中,被视为中国人群基因组核心序列,可能与中国人群特有的较为稳定的生物学功能或表型特征相关(图3)。
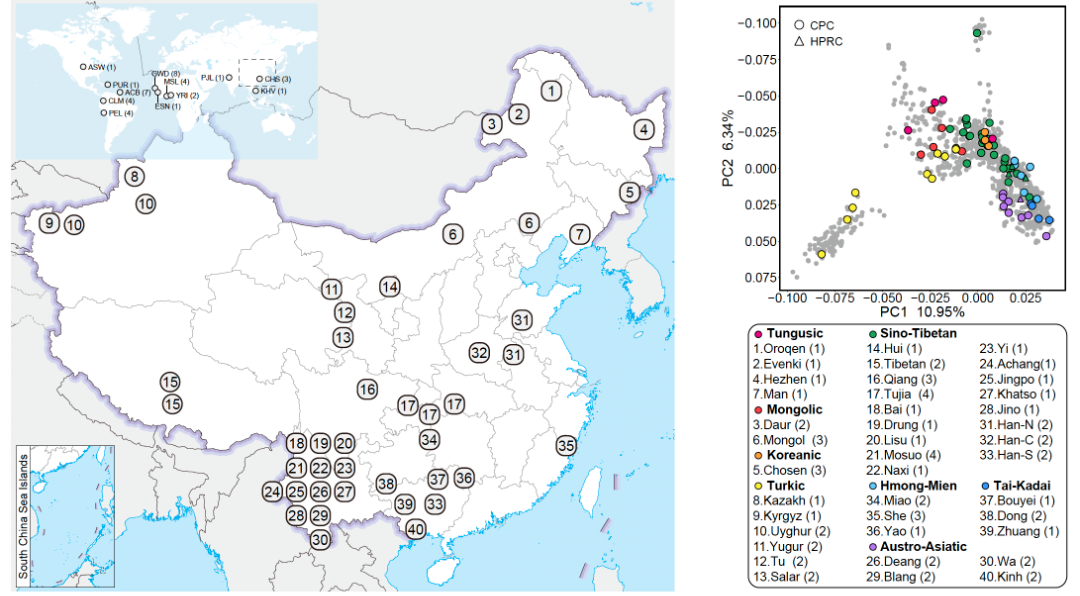
图3.核心样本地理分布及语系、族群、遗传聚类关系
CPC泛基因组图谱作为首个中国人群专属的泛基因组参考图谱,与HPRC泛基因组图谱相比,在中国人群特有的复杂变异解析方面具有显著优势。CPC泛基因组图谱中新发现了1079个基因拷贝数变异,以及包含药物代谢基因CYP2D6等在内的在中国人群中富集而在其他世界人群中出现频率较低的若干基因拷贝数变异;新鉴定出富集在中心粒、端粒等染色体复杂区域的3.4万个结构变异,其中半数以上仅在单个或两个样本中出现——若不针对中国丰富的族群多样性开展专门研究,将没有机会发现这些遗传变异(图4)。

图4.图形化泛基因组示例及中国人群特有复杂变异分布
研究人员进一步揭示,这些CPC新发现的遗传变异可能与亚洲人群特有的疾病易感性及表型多样性有关。一个典型的例子是α-珠蛋白基因簇,研究人员在该基因区域鉴定出两个中国人群特异性的大规模结构变异,包括一段20 kb的缺失序列和一段10 kb的重复序列,这将为进一步研究中国人群贫血症的遗传机理和致病机制提供新的线索(图5)。
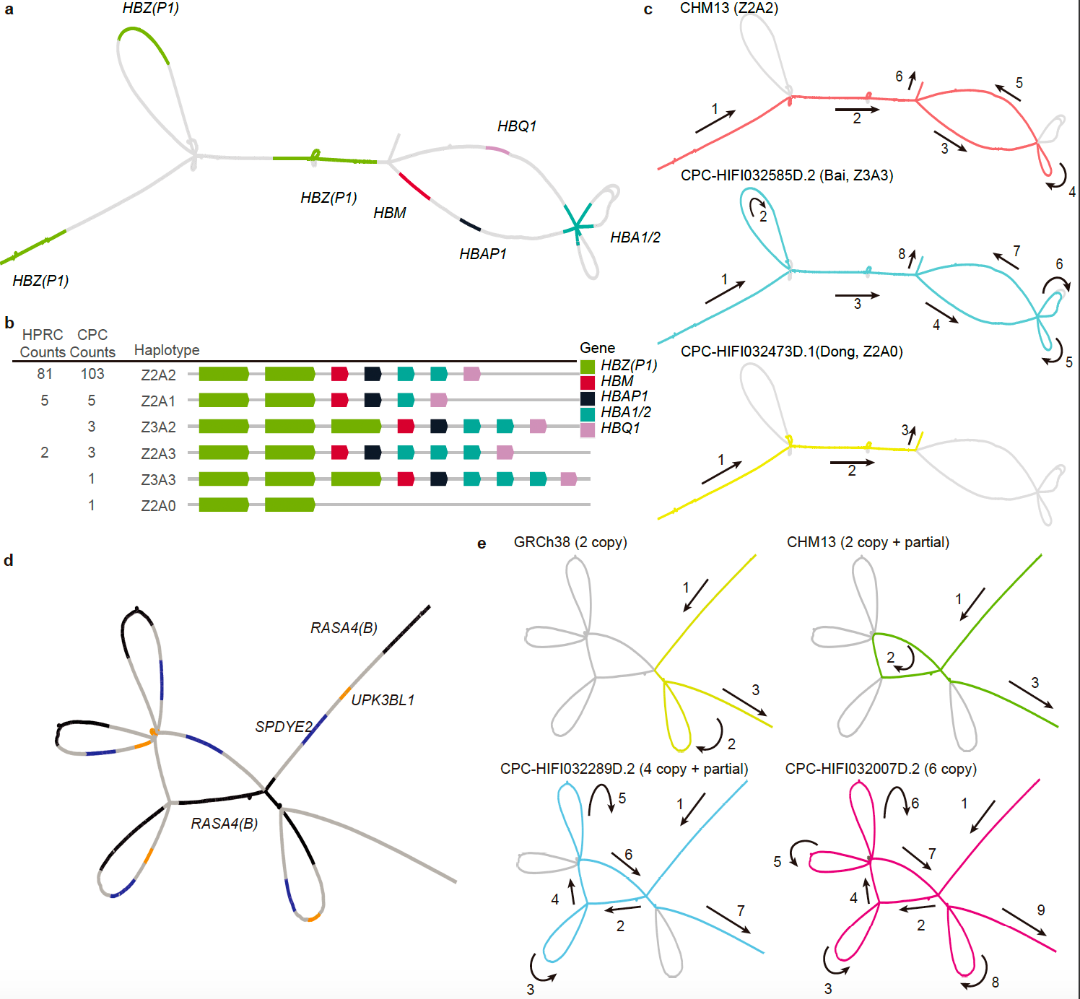
图5.CPC对我国族群特异的复杂基因组结构变异解析示例
同时,CPC新发现的遗传变异影响了具有潜在功能和经受过适应性进化的基因,这些基因可能与亚洲人群特有的疾病易感性及表型多样性有关,这也证实了将人群专属高质量泛基因组用于基因组学和医学研究的潜力和必要性。此外,研究人员在CPC参考图谱中发现了相当大比例的古人来源基因序列——平均每个族群和每个样本中分别有约15 Mb和约9.5 Mb的古人来源新序列——这可能是前期开展大量研究却未在现代人基因组中发现的古人基因渗入序列,或将为东亚现代人基因组中的古人基因渗入研究乃至整个古DNA领域提供新的信息资料和线索。
从人类基因组计划中国只承担“1%”的图谱绘制任务到今天中国人群泛基因组图谱“100%”由中国科学家完成,这项研究成果展现了中国生命科学尤其是基因组学科研水平在过去40年间的历史性跨越,为完整构建中华民族参考泛基因组打下了坚实的基础,也为人类参考泛基因组图谱绘制了独特的“中国画卷”。中国人群参考泛基因组不仅有助于中华民族共同体的遗传学研究,加深人们对个体或群体基因组的“异”与“同”更具象、更深度的认知,还将改变过去依赖主体基于欧洲白人的参考基因组而导致东亚特有罕见变异检出精确度难以提升的困境,从而提高我国生物医学数据分析的质量和效率,服务人民生命健康。
该项研究所涉及的样本信息和数据的公开发表已获得国家人类遗传资源管理部门批准。该项研究得到了国家自然科学基金重点项目、基础科学中心、国家重点研发计划等项目的资助。
内容及图片来源于基因科技网